a* 搜索算法实现原理( a-star )

a*搜索算法 动态演示分析 请参考 http://photo.jiajiajia.club/item/a-star.html
什么是a*搜索算法
A*搜寻算法,俗称A星算法,作为启发式搜索算法中的一种,这是一种在图形平面上,有多个节点的路径,求出最低通过成本的算法。常用于游戏中的NPC的移动计算,或线上游戏的BOT的移动计算上。该算法像Dijkstra算法一样,可以找到一条最短路径;也像BFS一样,进行启发式的搜索。
--------来自百度百科
a*搜索算法的核心公式(启发式函数)也即路径评分
F(n)= G(n) + H(n)
G(n)是开始节点到当前节点实际的移动代价
H(n)是当前节点到目标节点的预估移动代价(文章后边使用的是平方后的欧几里得距离来计算,或曼哈顿距离)
F(n)是G(n)和H(n)代价的总和
那么根据找个公式,可以首先想到搜索路径的过程中总是要F(n)值较小的那个 (即走的路径较近,距离目标节点也较近,那么遍历这个节点的价值就高)。
算法描述
首先有两个集合1.优先队列openList【后面搜索过程中将要被关注的集合元素】,2.closeList搜索过程中后面不需要关注的集合
1.将开始节点放进优先队列
2.如果优先队列中还有元素
3.从优先队列中取出一个元素(F(n)值最小的元素)
4.遍历该元素的相邻元素(上下左右四个方向,条件是该节点没有被遍历过,即不是openList或closeList中的数据),计算其fn,gn,hn的值。并将其加入优先队列。
5.如果该元素是目标节点,即结束算法,找出最短路径(输出)
6.如果该元素不是目标节点,将此元素加入closed【此后搜索过程中不需要被关注的集合元素】列表,然后继续执行过程 2
那么了解了启发式函数,和算法描述以后就已一个例子来可以大致分析一下算法过程
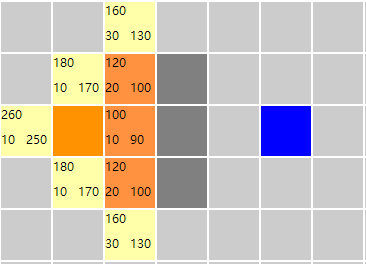
案例:求红色节点到蓝色节点的路径
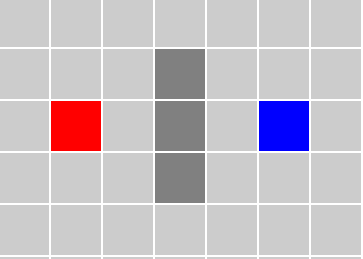
根据对上述算法的理解,开始先将红色节点加入优先队列中,然后从优先队列中取出一个元素(如果队列中有元素),那么当前节点明显不是目标节点,那么将其加入closeList列表,然后遍历其周围的四个方向的节点,并且计算出fn【左上角】,gn【左下角】,hn【右下角】的值,而且还要记住他的父节点是哪一个(即从来过来的)一会还要反过来推他的路径,最后将其加入优先队列中。
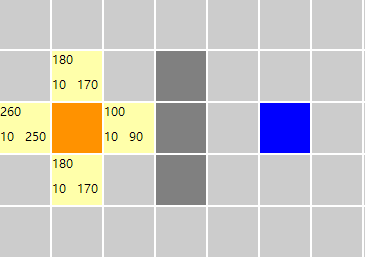
此时优先队列中的有四个元素(不为空),然后取出一个fn值最小的元素,即取出fn值为100的元素,然后执行的过程和上边执行的过程一样。执行完以后如下图
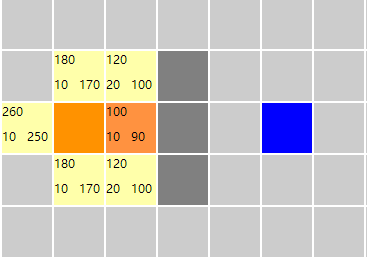
此时优先队列中有5个元素【五个黄色的节点,橘红色节点为closeList中的节点,即已经遍历过的节点】,但是目前还没有到达目标节点。继续搜索,那么此时openList中有两个fn值最小的元素,选哪一个呢?随缘吧~
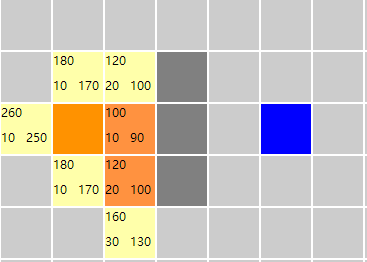
按照算法描述继续搜索
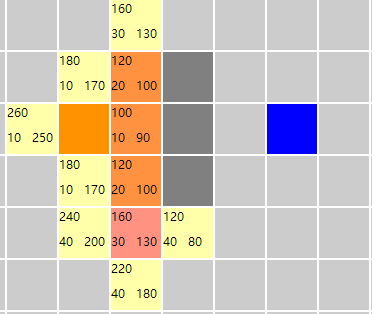
此处省略3张图........
直到最后遍历到下边这样

就快找到答案了,此时优先队列中有12个元素,fn值最小的是80那个节点的元素,也是目标节点元素。那么下一步将是~
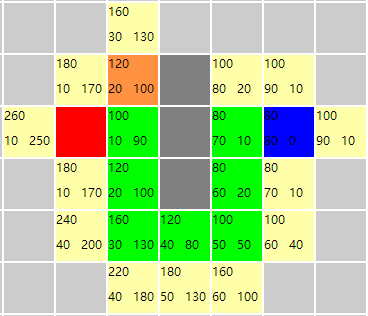
最终遍历到了目标节点,算法结束。
因为每次加入openList结合中的节点都记录了父节点的信息,那么就可以通过目标节点开始往前推,最终到达开始节点,那么这条路径就是我们要找的那条路径。
a*的实现原理就介绍完毕了。
fixed
没有一个冬天不可逾越,没有一个春天不会来临。最慢的步伐不是跬步,而是徘徊,最快的脚步不是冲刺,而是坚持。